|
|
|
|
|
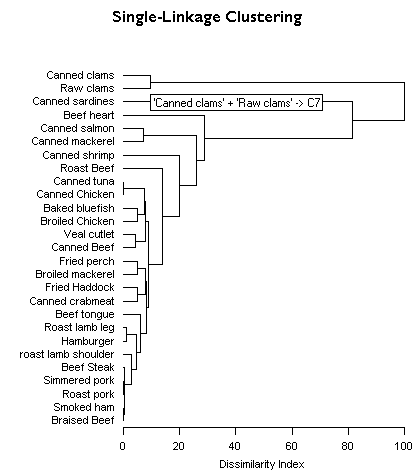
Pattern Recognition Chemetrica provides routines for unsupervised pattern recognition (Hierarchical Cluster Analysis) where the aim is to find groups in the data, and supervised pattern recognition (k-Nearest Neighbours and Linear Discriminant Analysis) where group membership is already known. Hierarchical Cluster Analysis (HCA) Features
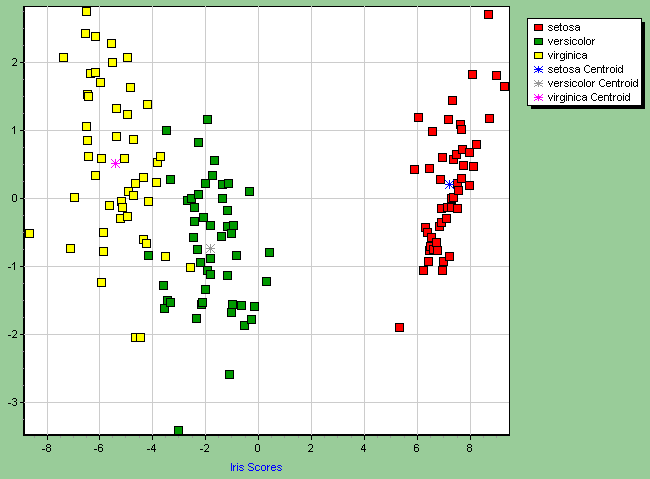
K-Nearest Neighbours (KNN) Builds classifier using up to a user-specified maximum number of neighbours. Leave-one-out classification is used to select the model with the fewest misclassification errors. The model can be changed by the click of a button. Linear Discriminant Analysis (LDA) Generates discriminant functions which can be used for prediction. Classifies training set using posterior probabilities. Prior probabilities for group membership can be assigned as equal for each group, proportional to the number of training objects in the group, or user specified values. Canonical discriminant scores are calculated. A plot of these scores shows how the objects are arranged into groups.
The above chart was actually generated by our chart server, which allows us to embed custom charts into an Excel worksheet. The chart server is still under development and will complement our existing COM servers.
|